. . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
Das Universum in der Nußschale, p. 91.
- ... F5)1.4
- In recent years, the `mirror neurons' became more popular (Rizzolatti et al., 2001). These neurons also fire when the monkey sees the grasping movement done by someone else. They have been therefore linked to imitation. However, this thesis does not deal with imitation.
- ... associations1.5
- No experiment can show that all forms of perception depend on action. On the contrary, Goodale and Milner (1992) argued that visual processing has two different streams, only one of them relates to action. It is still possible though that these different streams strongly interact (Franz et al., 2003). How far the two streams actually differ is still debated.
- ... requirements1.6
- The review is based on his concept of anticipation. There, a series of overt stimuli and overt responses is simulated.
- ... time1.7
- In these networks, the time can be continuous or discrete. However, this thesis only considers discrete-time models.
- ... array1.8
- Here, for simplicity, the discussion is limited to square grids, which are the most common, but the algorithm is not restricted to them; for example, hexagonal grids were also used (Kohonen, 1995).
- ... variables2.1
- In this thesis, the `motor variables' may also be proprioception, like, for example, the posture of a robot arm.
- ... distances2.2
- Here, the discussion is limited to the Euclidean distance, other measures like the Holder norm, or the Minkowski norm were also used (Linde et al., 1980).
- ...startmid)3.1
- Here, MPPCA behaves the same as MPPCA-ext, since the extensions do not matter.
- ... digit3.2
- The number of training patterns is different in Möller and Hoffmann (2004), where in total 60 000 patterns were used for the
8×8 image set.
- ... set4.1
- The data are from http://www.vision.caltech.edu/html-files/archive.html.
- ... database4.2
- The database is available at http://faces.kyb.tuebingen.mpg.de.
- ... space)4.3
- Boundary effects are ignored. For large m, they probably have only a minor effect.
- ...-sphere4.4
- An r-sphere is a hyper-sphere embedded in an r-dimensional space.
- ... space5.1
- An alternative might by principal curves and surfaces (Hastie and Stuetzle, 1989). However, kernel PCA has been shown to outperform them (Mika et al., 1999).
- ... components)5.2
- The tilde indicates an eigenvector that belongs to the centered data (section 2.4.2).
- ... kinematics6.1
- This is a technical shortcut to avoid using a controller that brings the end-effector close to the table surface. The use of the inverse kinematics may be interpreted as an external teacher that guides the arm to random positions on the table.
- ... values6.2
- Using an RNN to compute with population codes, instead of extracting the value of the stimulus, was also suggested by Pouget et al. (2003). The authors reviewed computational studies that refer to neuroscience, but did not mention robotics studies.
- ... objects6.3
- The model of Uno et al. (1995) recognized objects by associating pictures with prehensile hand shapes using an auto-associative network.
- ... constancy6.4
- Object constancy means that an object can be recognized independently of the perspective and the illumination.
- ... right)7.1
- A DFK 4303/P camera and a Pentax TS2V314A lens were used.
- ... vectors7.2
- This is different for auto-associative networks with bottleneck hidden layer. For them, it can be shown that the column vectors of
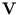 tend to the principal components of the distribution
{
tend to the principal components of the distribution
{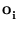 } (Diamantaras and Kung, 1996). Thus, for bottleneck networks, the column vectors are orthogonal.
} (Diamantaras and Kung, 1996). Thus, for bottleneck networks, the column vectors are orthogonal.
- ... movements7.3
- An improvement would be a robot using only two driven wheels and caster wheels, which turns on a floor more easily.
- ... smallC.1
- For the MLP, the square error stayed below 2.4 pixels squared, which is low compared to the range of values observed in figure 7.4: the square difference between the largest and the smallest value is about 500 pixels squared.
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . .